Процесс обработки хроматографического сигнала состоит из нескольких этапов: фильтрация шумов, разметка пиков, идентификация пиков, градуировка, количественный расчет. В этой статье мы рассмотрим один из наиболее важных вопросов — разметку пиков и их основные параметры. Мы расскажем как происходит разметка пиков на примере программы NetChrom, разработанной компанией «Мета-хром».
- Главные параметры пиков
- Типы хроматографических пиков
- Автоматическая разметка пиков
- Ручная разметка пиков
- Идентификация пиков:
- по абсолютному времени удерживания
- по относительному времени удерживания
- по относительному объему удерживания
- по времени удерживания и соотношению интенсивностей пиков на параллельно (последовательно) работающих детекторах
- по индексам удерживания (Ковача)
- по температурам кипения
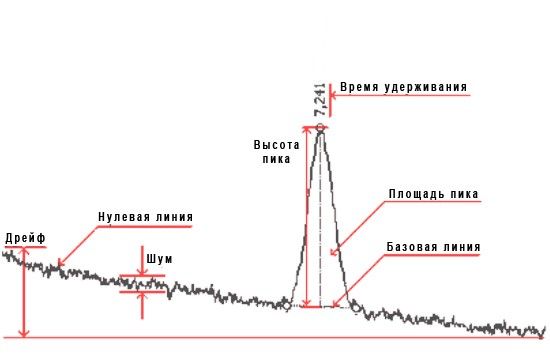
Главные параметры пиков
Разметка пиков (интегрирование) — операция вычисления параметров пиков, полученных на хроматограмме путем определения характерных точек (начало, вершина и конец пика). При этом пики ограничиваются базовой линией (прямой, соединяющей точки начала и конца пика на нулевой линии), которая проводится по методу «резиновой ленты», натягивающейся снизу от точки начала до точки конца базовой линии на протяжении всей хроматограммы.
На основании вычислений оцениваются основные параметры пика:
- время удерживания — время от начала анализа до максимума пика;
- площадь — область, заключенная между пиком и ограничивающей его базовой линией;
- ысота — расстояние между базовой линией и максимумом пика;
- ширина пика на половине его высоты.
Важно! Особенностью программы NetChrom является полностью автоматизированный процесс ее настройки под конкретный хроматографический сигнал, непрерывное отслеживание изменения характеристик хроматографического сигнала в ходе обработки хроматограммы: уровня шумов и дрейфа, а также уровня самого сигнала.
Для определения характерных точек пиков: начала, конца и вершины — в программе NetChrom используется алгоритм на основе вычисления первой сглаженной производной хроматографического сигнала, скорректированной на дрейф базовой линии.
При превышении или достижении определенного уровня этой производной, называемой порогом, определяются характерные точки пиков. Уровень порога определяется на основе шума производной на участках хроматографического сигнала, свободного от пиков.
Кроме уровня шума, дрейфа и уровня сигнала, большое значение имеет также зависимость изменения ширины хроматографических пиков от времени их удерживания в процессе анализа (ширина пика в начале и в конце анализа).
Как известно, ширина хроматографических пиков непрерывно увеличивается в процессе анализа, причем в изотермическом режиме эта зависимость имеет линейный характер, в режиме программирования температуры колонок эта зависимость имеет более сложный характер. Программа использует эту зависимость для автоматической настройки программных фильтров под хроматографический сигнал во время анализа.
Кроме этого, пользователю предоставлена возможность сформировать или отредактировать зависимость изменения ширины хроматографических пиков от времени удерживания самостоятельно (ширина пиков в начале и в конце хроматограммы).
При неправильном задании этой зависимости возможно некорректное определение характерных точек пика и даже пропуск небольших пиков. Зависимость изменения ширины хроматографических пиков от времени индивидуальна для каждого метода, и после изменения условий анализа: температуры колонок, расхода газоносителя и др., необходимо откорректировать зависимость.
Типы хроматографических пиков
Пики могут быть нескольких типов:
- простые пики — начало и конец пика принадлежат базовой линии;
- хвостатые пики — асимметрия заднего фронта пика;
- пики наездники — пики на хвосте большего по величине пика;
- неразделенные пики — конец первого пика совпадает с началом второго и эта точка не принадлежит базовой линии;
- зашкаленные пики — пики с плоской вершиной.
Разделение слившихся пиков производится по перпендикуляру или тангенте в зависимости от соотношения ширины и высоты этих пиков.
Пики наездники отделяются по тангенте и площадь под ними включается в площадь хвостатого пика.
Следует иметь в виду, что никакой алгоритм не может в ряде случаев гарантировать корректную разметку на пики, поскольку само понятие «пик» во многом субъективно и зависит от конкретной аналитической задачи. Например, нельзя гарантировать корректную разметку на пики при сложной форме базовой линии, плохом разделении хроматографических пиков, малых пиках-наездниках, высоком уровне шумов и так далее.
При этом правильность получаемых результатов зачастую зависит от опыта пользователя. В программе NetChrom реализованы два подхода для проведения разметки пиков:
- автоматическая разметка пиков;
- ручная (графическая) разметка пиков.
Ниже мы рассмотрим каждый из подходов более детально.
Автоматическая разметка пиков
Автоматическая разметка пиков (интегрирование) имеет смысл тогда, когда ожидается обработка серии хроматограмм со сходными, повторяющимися особенностями базовой линии, значениями величины и последовательностью хроматографических пиков.
Параметры интегрирования, с помощью которых пользователь может влиять на процесс обнаружения пиков на хроматограмме, представлены ниже:
Ширина

Пороги
Порог обнаружения пиков может быть задан по двум параметрам: минимальной площади и минимальной высоте пика.
- Минимальная площадь
Минимально допустимая площадь детектируемого пика. При детектировании пиков имеется возможность не размечать или подавлять пики, площадь которых меньше заданной. При этом значение параметра, равное 0, означает, что подавление пиков выключено.

- Минимальная высота
Минимально допустимая высота детектируемого пика. Подавление пиков с высотой значение которой, меньше заданного. При этом значение параметра, равное 0, означает, что подавление пиков выключено.

Не всегда получается подобрать одинаковые параметры для разметки всех пиков. Например, с увеличением времени выхода пика, изменяется его ширина, поэтому значения параметров, подходящие для пиков в начале хроматограммы, могут не подходить для пиков в ее конце. В таких случаях рекомендуется использовать события интегрирования.
Настройка алгоритма разметки с использованием событий интегрирования имеет смысл, если ожидается серия однотипных хроматограмм со сходными, повторяющимися особенностями базовой линии. События интегрирования позволяют настроить процесс разметки в соответствии с особенностями данной серии хроматограмм, задавая для некоторых участков хроматограмм индивидуальные параметры и правила разметки.
Событие можно задать для отдельного детектора, и оно начинает действовать с указанного момента времени до тех пор, пока не будет переопределено другим событием такого же типа, или пока не завершится хроматограмма. Если не удается добиться желаемой разметки при использовании параметров и событий интегрирования, используют ручное графическое интегрирование (непосредственно на графике хроматограммы).
Ручная разметка пиков
Ручная разметка пиков используется, если не удается добиться желаемой разметки при использовании параметров автоматической разметки. Ручная графическая разметка пиков производится непосредственно на графике хроматограммы. При этом все действия, выполняемые пользователем, относятся к выделенному фрагменту хроматограммы или к выделенному пику. В программе существуют следующие типовые операции по ручному редактированию пиков на хроматограмме:
- создание пика;
- разделение пика;
- слияние пиков;
- корректировка положения характерных точек пика;
- задание пика наездником;
- задание пика хвостатым;
- задание пика базовым;
- задание пика слившимся;
- удаление пика;
- удаление пиков справа;
- удаление пиков слева;
- удаление всех пиков.
Идентификация пиков
Идентификация — отнесение пиков на хроматограмме к тому или иному компоненту из списка компонентов рабочего метода. При этом производится сравнение рассчитанных параметров удерживания всех обнаруженных на хроматограмме пиков с информацией, хранящейся в таблице компонентов. Идентификация компонентов по одному или по нескольким детекторам осуществляется следующими способами:
- по абсолютному времени удерживания;
- по относительному времени удерживания;
- по относительному объему удерживания;
- по времени удерживания и соотношению интенсивностей пиков на параллельно (последовательно) работающих детекторах;
- по индексам удерживания (Ковача);
- по температурам кипения.
Теперь рассмотрим каждый из вышеперечисленных способов подробнее.
Идентификация по абсолютному времени удерживания
Наиболее простой способ идентификации — по времени удерживания, то есть сравнение времени удерживания анализируемого компонента со временем удерживания известного соединения при строго заданных условиях анализа. Для проведения идентификации пика по времени удерживания в библиотеке компонентов должна содержаться информация:
- наименование компонента;
- время удерживания;
- окно поиска по времени (в единицах времени).
Окно поиска — границы области, в которой будет осуществляться поиск пика как в положительную, так и в отрицательную сторону от заданного в таблице параметра удерживания.
При задании окна необходимо стремиться, чтобы его ширина была достаточной для попадания пика в окно при неизбежных изменениях времени удерживания, но и не слишком большой, чтобы в него не попадали соседние пики.
В случае если в окно поиска попадают несколько пиков, то среди них выбирается пик, имеющий максимальную вероятность идентификации (наиболее интенсивный или ближайший к библиотечному времени).
Идентификация по относительному времени удерживания
При изменении условий в процессе анализа (расход газа-носителя, температура колонки), а также в процессе «старения» колонок, пики могут не попасть в окно поиска. Это происходит чаще всего:
- когда нельзя задать достаточно широкое окно поиска, чтобы в него не попали соседние пики;
- при длительных анализах с программированием температуры колонок, когда время удерживания может измениться в большей степени.
Выход из положения состоит в том, что один из пиков (или несколько) назначается «стандартом времени», для него задается увеличенное окно поиска (2-5%), а для остальных пиков рассчитывается относительное время удерживания.
Стандартом времени, как правило, выбираются стоящие отдельно или большие пики обязательно присутствующие на хроматограмме. Таким образом, при одновременном сдвиге по той или иной причине времен удерживания всех компонентов, наличие пиков-стандартов времени поможет правильно идентифицировать вещества, несмотря на то, что их время удерживания не будет попадать в окно поиска по времени.
В этом случае идентификация производится следующим образом:
- производится поиск пика стандарта времени по времени удерживания;
- для стандарта времени удерживания рассчитывается коэффициент отклонения реального времени удерживания по сравнению с библиотечным временем по формуле:
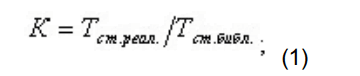
для остальных пиков рассчитывается ожидаемое время удерживания, исходя из времени, заданного в библиотеке для данного компонента, и рассчитанного коэффициента отклонения времени стандарта по формуле:
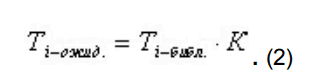
Идентификация по относительному объему удерживания
Является более точным расчетным параметром по сравнению с относительным временем удерживания, так как в нем учитывается время на прохождение подвижной фазой расстояния от устройства для ввода пробы до детектора (иногда это время называют «мертвым» временем или временем удерживания несорбирующегося вещества).
При этом относительный объем удерживания стандарта времени принимают за единицу, а относительный объем удерживания компонентов (Ri) рассчитывают по формуле:
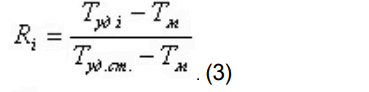
T уд i — время удерживания анализируемого компонента;
T уд.ст. — время удерживания стандарта времени;
T м — мертвое время.
Идентификация по времени удерживания и соотношению интенсивностей пиков на параллельно (последовательно) работающих детекторах
Если в процессе анализа используются несколько (чаще всего два) параллельно или последовательно работающих детектора, то для более достоверной идентификации можно применить способ идентификации, заключающийся в том, что наряду со временем удерживания (абсолютным или относительным), можно использовать отношение интенсивностей пиков соответствующих детекторов.
Вначале пик идентифицируется по времени удерживания на ведущем детекторе (детекторе, по интенсивности пика которого рассчитывается концентрация компонента). Затем сравниваются отношения интенсивностей пика на различных детекторах с библиотечным отношением.
Для идентификации может использоваться не только отношение интенсивностей, но также наличие или отсутствие пика на другом (не ведущем) детекторе.
Идентификация по индексам удерживания (Ковача)
Для идентификации могут использоваться и другие относительные параметры удерживания, которые в меньшей степени зависят (в отличие от времени удерживания) от условий анализа. Одним из таких параметров является индекс удерживания — безразмерная величина, характеризующая положение пика вещества на хроматограмме относительно пиков выбранных стандартов.
Если в качестве стандартов используются насыщенные углеводороды (алканы, парафины), то индекс удерживания называется индексом Ковача. Выбор типа индекса (линейный или логарифмический) зависит от условий анализа.
Для постоянной температуры колонки во время анализа характерна логарифмическая зависимость, при программировании — линейная. Однако между этими двумя зависимостями нет четкого разделения, поэтому при применении режима программирования температуры колонок с начальным изотермическим участком, используется смешанный тип индекса. При этом на изотермическом участке выбирается логарифмический тип индекса, до первого реперного пика, который попадает на участок программирования температур, и в дальнейшем — линейный тип индекса.
Начало программирования температуры колонок выбирается согласно заданным параметрам управления соответствующего метода. При идентификации по индексам удерживания в таблицу компонентов должны быть занесены табличные значения индекса компонентов и ширина окна поиска по индексу. Пикам – стандартам индексов удерживания необходимо присвоить тип: реперный в таблице компонентов и задать увеличенное окно поиска (2-5%) от времени удерживания.
Идентификация по индексам удерживания производится следующим образом:
- Производится идентификация реперных пиков по времени удерживания.
- Реперным пикам присваиваются соответствующие индексы из таблицы компонентов.
- Используя индексы удерживания реперных пиков, рассчитываются индексы удерживания обычных пиков и сравниваются с табличными данными.
Индексы удерживания Ковача рассчитываются по формулам:
линейный индекс удерживания:
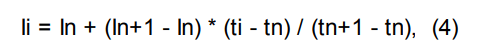
логарифмический индекс удерживания:
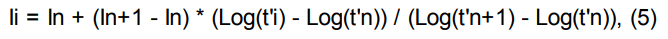
где:
Ii — время удерживания интересующего пика;
In, In+1 — индексы предыдущего и последующего компонентов с известной величиной индекса;
ti — время удерживания интересующего пика;
tn, tn+1 — времена удерживания пиков, соответствующие предыдущему и последующему компонентам с известными индексами;
t'... — приведенное время удерживания.
Важно! Для увеличения точности расчета индексов удерживания в качестве времени удерживания необходимо брать приведенное время удерживания. Приведенное время удержания равно разности абсолютного времени удержания и мертвого времени (времени нахождения неудерживаемого компонента в хроматографической системе).
Мертвое время определяется либо экспериментально, либо расчетом, выполненным с помощью газового калькулятора. В качестве неудерживаемого компонента чаще всего используют метан.
В окно ожидаемого времени или индекса удерживания одного компонента может попасть несколько пиков. В этом случае выбор пика, в зависимости от настройки, может осуществляться по следующим критериям:
- ближайший к ожидаемому (библиотечному) времени или индексу удерживания;
- максимальный по высоте;
- максимальный по площади.
Один и тот же пик может попасть в окна поиска разных компонентов, в этом случае необходимо уменьшить ширину окон поиска.
Указанная схема распознавания (идентификации) компонентов оказывается достаточно универсальной и гибкой для того, чтобы проблема корректного распознавания пиков в подавляющем большинстве случаев было решена. Все, что требуется от оператора — на этапе настройки грамотно выбрать пик стандарта времени или реперные пики и в дальнейшем периодически корректировать их ожидаемые времена удерживания по текущей хроматограмме.
Идентификация по температурам кипения
Частным случаем расчета индексов удерживания является расчет температур кипения. При расчете температур кипения используются те же формулы, что и при расчете индексов. Для расчета температур кипения необходимо в библиотеке методов выбрать тип индекса (линейный или логарифмический) и задать известные температуры кипения реперных компонентов.